 Neiro
NeiroTurboQuant
Экстремальное сжатие KV‑кеша LLM без потери точности
Александр И.
Редактор Neirostack
Доступен в РФ
TurboQuant: сжатие KV‑кеша без потери точности
TurboQuant — это набор алгоритмов векторной квантизации, представленных исследователями Google в марте 2026 года. Основная цель работы — устранить «memory overhead», типичный побочный эффект традиционных методов квантизации, когда для каждого блока данных необходимо хранить полноценные константы квантизации. Авторы предлагают два вспомогательных метода — Quantized Johnson‑Lindenstrauss (QJL) и PolarQuant — которые вместе позволяют достичь почти безупречного сжатия ключ‑значения (KV) кеша large language models (LLM) без ухудшения качества внимания.
Как работает TurboQuant
Алгоритм состоит из двух этапов. На первом шаге данные векторы случайным образом вращаются (метод PolarQuant). Это преобразование переводит векторы из декартовых координат в полярные, где радиус отражает magnitude вектора, а угол — его направление. Благодаря предсказуемому распределению углов можно избежать дорогих этапов нормализации и хранить информацию в фиксированной круговой сетке, устраняя необходимость в дополнительных битах для границ блоков.
На втором шаге к небольшому остаточному ошибке применяется QJL — однобитовый оператор, основанный на преобразовании Джонсона‑Линденштрауса. QJL превращает каждый компонент остаточного вектора в знак ±1, требуя нулевой дополнительной памяти для хранения квантизационных коэффициентов. При этом используется специфический оценщик, который компенсирует wprowadzoną ошибку, сохраняя точность вычисления attention scores.
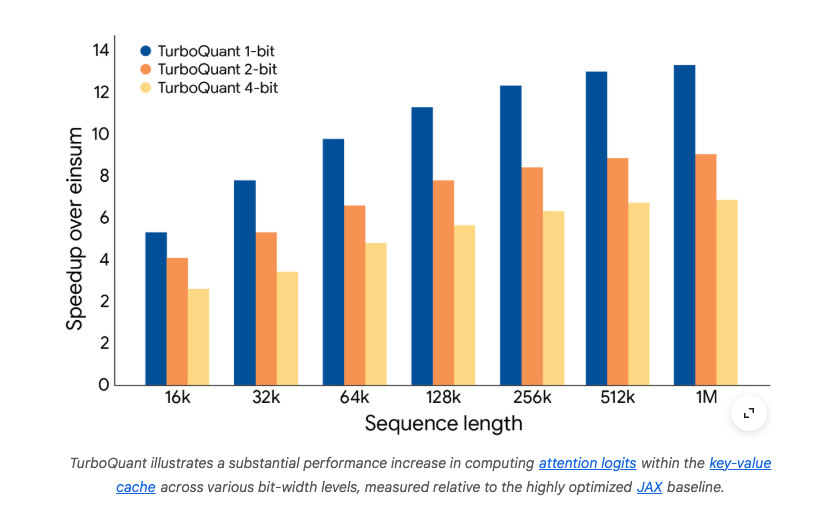
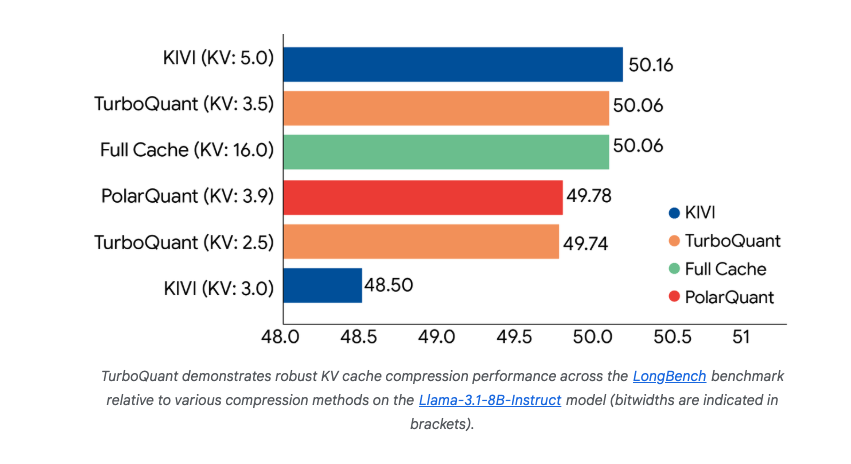
В результате TurboQuant способен закодировать KV‑кеш в 3‑бита (или даже меньше) при полном отсутствии потери точности на стандартных тестах long‑context (LongBench, Needle‑In‑A‑Haystack, ZeroSCROLLS, RULER, L‑Eval). При этом показатели скорости возрастают: на GPU H100 4‑битовый TurboQuant обеспечивает до 8× ускорение вычисления attention logits относительно 32‑битного базового варианта.
Практические implications для разработчиков и исследователей
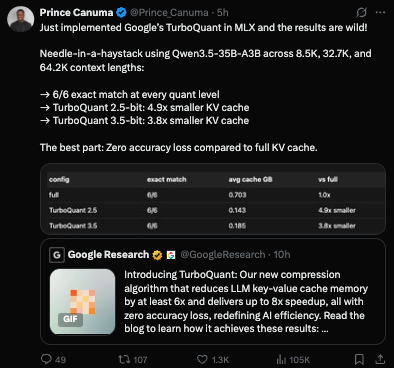
Для инженеров, работающих с большими языковыми моделями (например, Gemini, Llama‑3.1), TurboQuant открывает возможность сократить объём памяти, выделяемой под KV‑кеш, в несколько раз без необходимости переобучения или fine‑tuning модели. Это особенно актуально для сценариев длинного контекста: генерация кода, суммаризация больших документов, поиск по семантическим векторам.
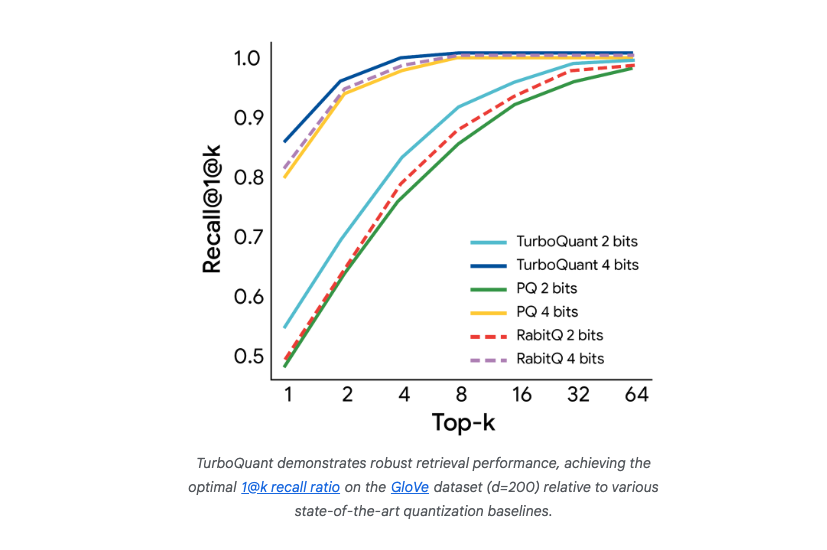
Векторный поиск также получает выгоду: алгоритм демонстрирует superior 1@k recall по сравнению с baseline‑методами (Product Quantization, RabbiQ) при работе с высокоразмерными эмбеддингами (например, GloVe d=200). Благодаря нулевому memory overhead и минимальному препроцессингу, построение и запрос больших векторных индексов становятся значительно быстрее и дешевле.
Ограничения и открытые вопросы
- Текущая реализация представлена в виде исследовательского кода (JAX/TensorFlow). Нет готового пользовательского интерфейса или API‑сервиса, который можно было бы сразу интегрировать в продукт.
- Для применения в продакшене необходима адаптация под конкретную инфраструктуру модели (формат весов, слой attention). Это может потребовать дополнительных инженерных усилий.
- Хотя алгоритмы teoretically не требуют обучения, в реальных системах может понадобиться калибровка гиперпараметров (размер блока, количество итераций полярного преобразования) для достижения оптимального trade‑off между скоростью и точностью.
- Доступ к исходным материалам (препринт, код) осуществляется через открытые репозитории Google Research; однако некоторые сервисы Google могут быть ограничены в России, что косвенно усложняет загрузку материалов без VPN.
Вывод
TurboQuant представляет собой теоретически обоснованный и практически эффективный подход к экстремальному сжатию KV‑кеша и векторных индексов. Для российских разработчиков, работающих с LLM и крупномасштабным векторным поиском, алгоритм может стать полезным инструментом оптимизации ресурсов, при условии готовности инвестировать время в интеграцию и тестирование. Отсутствие готового коммерческого продукта и потенциальные барьеры с доступом к инфраструктуре Google делают его пока более подходящим для исследовательских и ранних adopter‑проектов, чем для готового «plug‑and‑play» решения.
Скриншоты интерфейса

Плюсы
- ✓ Сжатие KV‑кеша до 3‑бит без потери качества внимания /n Ускорение attention‑вычислений до 8× на современных GPU /n Уменьшение памяти под векторные индексы, улучшение скорости поиска /n Не требует переобучения или fine‑tuning базовой модели /n Теоретически обоснован, работает близко к нижним пределам сжатия
Минусы
- • Отсутствует готовый пользовательский интерфейс или облачный API /n Требует инженерных работ по интеграции в существующие pipelines /n Потенциальная необходимость калибровки гиперпараметров под конкретную модель /n Доступ к исходному коду и материалам может потребовать VPN в России /n На данный момент ориентирован primarily на исследовательское использование